Imagine you are writing a Logic App or a Power Automate flow and you want to transfrom the following data structure:
{
"books": {
"book": [
{
"title": "Bullshit Jobs: A Theory",
"author": "David Graeber"
},
{
"title": "Fragments of an Anarchist Anthropology (Paradigm)",
"author": "David Graeber"
},
{
"title": "In Praise of Idleness",
"author": "Bertrand Russell"
}
]
}
}
into something like this:
[
{
"author": "David Graeber",
"books": [
"Bullshit Jobs: A Theory",
"Fragments of an Anarchist Anthropology (Paradigm)"
]
},
{
"author": "Bertrand Russell",
"books": [
"In Praise of Idleness"
]
}
]
What type of transformation is done here? For each author we need to create an array of all the author’s books. A straight forward approach would be to use the filter array action.
But there are two problems here:
- How do we know which authors exist in the list and how do we deal with authors (like “David Graeber”) that appears several times in the list?
- Even after filtering the list down to books by “David Graeber”, how do we manage to merge the resulting book titles into a single array?
Tasks like this are not uncommon but often quite tricky to solve without using several for-each loops and conditions, which would inflate the workflow unnecessarily and make it hard to read.
This is where XPath comes into the picture. XPath is a language used to navigate and query XML documents. In simple terms, XML documents are like trees, where each element is a node in the tree. XPath allows you to specify a path through this tree to locate specific nodes or groups of nodes.
Let’s take our example above. Converted to xml, it would look like this:
<?xml version="1.0" encoding="UTF-8" ?>
<books>
<book>
<title>Bullshit Jobs: A Theory</title>
<author>David Graeber</author>
</book>
<book>
<title>Fragments of an Anarchist Anthropology (Paradigm)</title>
<author>David Graeber</author>
</book>
<book>
<title>In Praise of Idleness</title>
<author>Bertrand Russell</author>
</book>
</books>
Using XPath, you can select nodes from this document based on their element name, or position in the document. And we can use this to solve the problems, stated above:
//author/text(): Selects the text value of allauthorelements that appear anywhere in the xml document.//author[text()="David Graeber"]/following-sibling::title/text(): This first selects theauthorelement that has"David Graeber"as a text value. From this node it determines the text value of the thetitleelement, that is its immediate sibling.
For more examples on XPath queries that can be used in Logic Apps and Power Automate see: xpath() - Reference guide for expression functions - Azure Logic Apps
Let’s see now, how these two XPath queries help us to transform the data in our example.
Transforming JSON data to XML
XPath only works on XML documents. In order to use XPath we will need to transform our JSON objects to XML first. This can be done using the xml() expression function, but there is a caveat:
⚠️ XML documents must have a single root element.
This means, that it is not possible to transform {"foo":[ "A","B","C"]} into xml, as this would be translated as:
<foo>A</foo>
<foo>B</foo>
<foo>C</foo>
Instead we have to provide a single root element to the data structure before attempting the conversion to XML: {"bar":{"foo":[ "A","B","C"]}}. This would translate into valid XML:
<bar>
<foo>A</foo>
<foo>B</foo>
<foo>C</foo>
</bar>
Accordingly in a Logic App we would do it like this:
![]()
The actual conversion to XML is then done in a compose action with the following expression:
xml(outputs('Compose_-_provide_root_element_to_books_array_for_xml_transformation'))
The output of this last compose action, is what we will be working with, when applying the XPath.
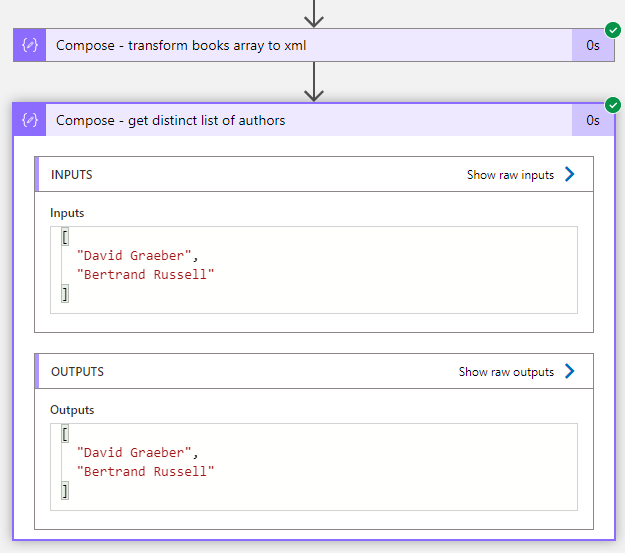
Getting a list of authors with distinct values
The following XPath query can be used to get a list of all authors from the XML in our example: //author/text(). To apply the XPath the expression function xpath() is used:
xpath(outputs('Compose_-_transform_books_array_to_xml'), '//author/text()')
This will result in a string array with all author names, but this list does not yet contain distinct values, which means that “David Graeber” would appear two times. While XPath offers functions that would allow to return distinct values, these functions are unfortunately not supported in Logic Apps and Power Automate.
Instead we can use the union() expression function. A trick, that I have explained earlier on this blog: Get distinct values from array in Logic Apps and Power Automate (manualbashing.github.io).
union(xpath(outputs('Compose_-_transform_books_array_to_xml'), '//author/text()'), json('[]'))
This will result in a list of authors. in which each author appears only once.
Get an array of book titles by author
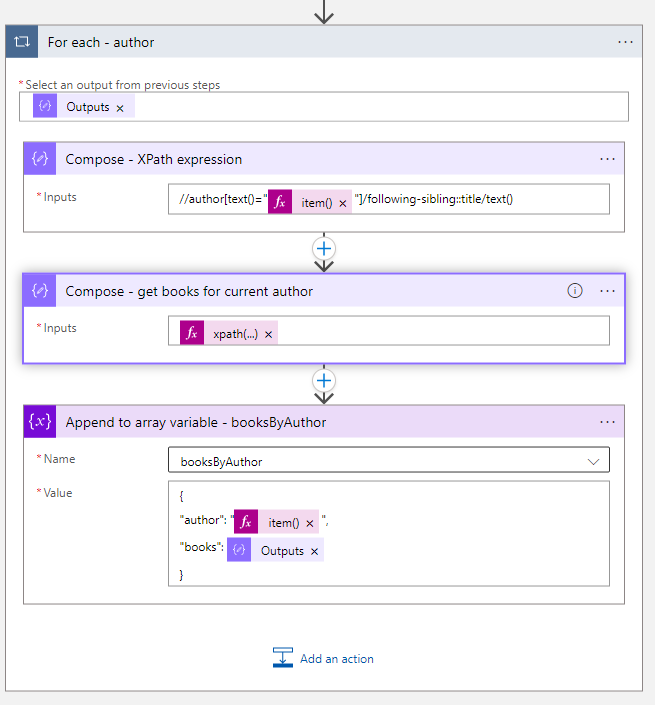
Now that we have list of all authors, a single for each loop will be enough to transform the data in the way, that we want.
First we interate over the list of authors to prepare an XPath query that will return the titles of all books of the current author:
//author[text()="@{item()}"]/following-sibling::title/text()
This first selects the author element that has the current author’s name as a text value. From this node it determines the text value of the the title element, that is its immediate sibling. The current author’s name is returned by the expression item(), which refers to the current element in the for each loop.
To execute the XPath query we use another compose step and add the following expression:
xpath(outputs('Compose_-_transform_books_array_to_xml'), outputs('Compose_-_XPath_expression'))
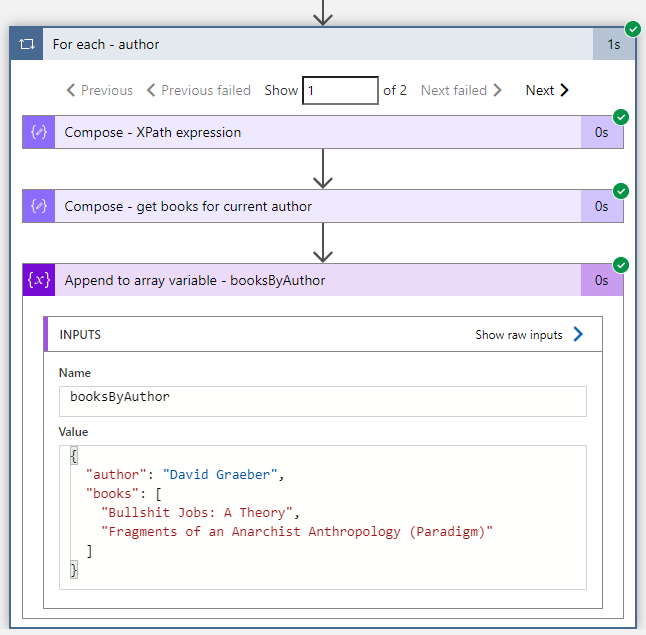
The result we can then arrange into a new object and add this to an array variable.
The result of our efforts looks like this:
⌨️ Example
To see this all in action, you can deploy a minimal example that I have added to my bicep-snippets repository: bicep-snippets/logicapp-msi-workspace at mother · manualbashing/bicep-snippets (github.com)